Introducing A Super-Intelligent AI That Can Perceive, Understand, And Reason In Multiple Modalities: Democratizing Kosmos-1
date
Apr 28, 2023
slug
free-superintelligence
status
Published
tags
Research
summary
Introducing A Super-Intelligent AI That Can Perceive, Understand, And Reason In Multiple Modalities: Democratizing Kosmos-1
type
Post

[Multi-modal AIs are advanced systems that can process and understand different types of data (such as text, images, audio, and video) and reason across these modalities.
This allows them to perceive, understand, and respond to the world more effectively compared to uni-modal AIs that only work with a single type of data like in the case of chatgpt text]
Grab a cup of tea, or perhaps something stronger, and prepare to chuckle as we explore the day in the life of hapless souls interacting with uni-modal AI systems that are as thick as a brick wall.
You know, like the one you might find in an old Scottish castle.
So picture this: our brave protagonist, let’s call him Angus, is trying to use his voice assistant to find some important information.
With a glint of hope in his eyes, he asks the AI a question. But, oh dear, the AI is clueless, completely missing the context of his query, and provides an answer that’s about as relevant as a kilt at a nudist beach.
Angus tries again, rephrasing his question, but the AI still doesn’t get it. Poor Angus is forced to dance a linguistic jig, trying to adapt to the limitations of this uni-modal buffoonery.
But wait, it gets worse!
Picture Angus now, using an image recognition app to identify an object.
He snaps a picture, only for the app to throw out guesses wilder than a drunken goat at a ceilidh.
Different angles, lighting conditions, nothing helps.
Angus is ready to toss his phone into the nearest loch in a fit of exasperation.
Now, as the great Steve Jobs once said, “Design is not just what it looks like and feels like. Design is how it works.”
And let me tell you, Angus’s current AI design certainly isn’t working like a well-oiled bagpipe.
But fret not, for there’s a bright horizon ahead. We’re talking about Multi-Modality AI, folks.
Superintelligent systems that can perceive, understand, and reason in multiple modalities, like a technological Swiss Army knife.
They’ll revolutionize how we interact with technology, leaving our friend Angus free to enjoy a dram of whisky without fear of being driven mad by his devices.
So, gather ‘round and join us as we embark on a journey to explore the future of AI, where frustration gives way to intuitive, seamless experiences.
After all, who wouldn’t want an AI that can do more than just baffle its users?
Cheers to that!
The Limitations of Uni-Modal AI: A Restricted & Limited Experience
Ladies and gentlemen, gather ‘round for another round of hilarity as we delve into the tragicomic world of the one-trick pony: the uni-modal AI!
That’s right, we’re talking about a system with all the intelligence of a soggy haggis.
Let’s take a wee look at the life of someone grappling with this doltish digital dunce.
Inability to Understand Context:

First off, we have the uni-modal AI’s inability to understand context.
Picture our dear protagonist, let’s call her Morag this time, trying to interact with an AI that’s more clueless than a sheep at a Mensa meeting.
She poses a question, only to be met with baffling responses and incorrect interpretations.
No matter how she rephrases or clarifies her intent, the AI just doesn’t get it.
Morag’s patience wears thinner than a well-worn kilt as she wrestles with this feeble-minded automaton.
Lack of Adaptability:

Next up, we have the distinct lack of adaptability.
Aye, these uni-modal systems are about as flexible as a frozen caber.
You see, Morag might find herself in a new situation, and this daft AI system has no idea how to recognize or adapt to it.
Morag’s left to her own devices (pun intended) to find a workaround, all the while cursing the day she met this rigid digital dimwit.
Poor User Experience:
And now, the pièce de résistance, the poor user experience.
Uni-modal AI systems force users like our Morag to bend over backward, adapting to their limitations rather than the other way around.
It’s enough to make anyone feel like they’re trying to teach a goldfish to play the bagpipes.
But fear not, for there’s hope on the horizon!
We must leapfrog beyond the uni-modal AI swamp and embrace the potential of multi-modal AI systems.
By doing so, we can revolutionize how users interact with technology, transforming experiences from frustrating to enjoyable.
Think of it like trading in a rusty unicycle for a sleek, high-performance sports car.
The future of AI lies in multi-modal systems that can perceive, understand, and reason in multiple modalities, giving our Morag and her kin the intelligent and adaptable tools they so rightly deserve.
And who wouldn’t want that?
Slàinte mhath!
The Impact of Multi-Modal AI: A Seamless Experience
Now introduce the heroic multi-modal AI, the digital knight in shining armor, swooping in to save the day from the bumbling uni-modal AI buffoons.
In this brave new world of multi-modal AI, our protagonist, let’s call him Hamish this time, discovers the seamless experience he’s been dreaming of.
No more banging his head against a digital brick wall.
Multi-modal AI systems can process and understand information in multiple modalities, like text, images, audio, and video.
It’s like a bagpipe-playing octopus on roller skates! Well, maybe not quite, but you get the idea.
What’s special about multi-modal AIs is their capability to process and integrate information from multiple data types, which enables them to provide richer insights and more personalized interactions than uni-modal AIs.
For example, Users can supply various forms of data, such as text prompts, images, audio, or even a combination of these to interact with multi-modal AIs.
This provides flexibility in how they can engage with the AI and use it in their daily lives or work.
With Multi-Modal AI’s you can talk about an image, a pdf, or even a movie and the AI can fully reason in that type of data!
Improved Understanding of Context

With this newfound understanding of context, the multi-modal AI system grasps the subtleties of Hamish’s questions, anticipating his needs like a clairvoyant haggis whisperer.
This digital prodigy leaps over the hurdles of confusion and miscommunication, leaving the days of stubborn mule-like AI in the dust.
Imagine a multi-modal AI that can analyze both text and images, understanding the emotions behind a social media post.
No longer will Hamish be left wondering if his AI is interpreting sarcasm as sincerity or mistaking a grumpy cat meme for a philosophical treatise.
Multi-modal AI systems excel in understanding the context in which information is presented.
By processing information in multiple modalities, these systems can more accurately interpret user input, leading to a more seamless, intuitive experience.
For example, a multi-modal AI system could analyze both the text and images in a social media post to better understand the sentiment and emotions being conveyed, providing users with more accurate and relevant responses.
Greater Adaptability:

And let’s talk about adaptability, folks.
This multi-modal AI is a veritable chameleon, learning from its mistakes and adapting to new situations like a Highland warrior switching from claymore to dirk.
Whether it’s deciphering mumbled voice commands or interpreting ambiguous facial expressions, this AI has got Hamish covered.
Multi-modal AIs can adapt to users by interpreting and combining different types of input, making it easier for users to communicate their needs and preferences without having to conform to the limitations of a single modality.
Multi-modal AI systems are designed to learn from their mistakes and adapt to new situations, making them well-suited for tasks that require flexibility and adaptability.
For instance, a multi-modal AI system could analyze a user’s voice commands and facial expressions simultaneously to better understand their intent, even if their speech is unclear or ambiguous.
This adaptability allows multi-modal AI systems to provide more accurate and personalized assistance, enhancing the user experience.
Seamless User Experience:

Finally, we arrive at the seamless user experience, the Holy Grail of AI interaction.
No more must our dear Hamish contort himself to fit the constraints of technology.
This multi-modal marvel understands his preferences across platforms, providing personalized recommendations as if it’s been rifling through his diary.
By overcoming the limitations of uni-modal AI systems, multi-modal AI systems will provide seamless, intuitive user experiences.
People no longer need to adapt their behavior to the limitations of the technology, as the technology is designed to adapt to the user’s needs.
For example, a multi-modal AI system could understand a user’s preferences and habits across various platforms, such as music streaming, video streaming, and social media, to provide personalized recommendations that cater to the user’s unique tastes and interests.
Real-World Examples of Multi-Modal AI Systems
There are several examples of multi-modal AI systems that showcase the potential of this technology:
- Real-Time Companions: Real-time companions, such as Google Assistant and APAC AI’s Athena, are increasingly incorporating multi-modal capabilities, allowing them to understand and respond to user input across text, voice, and visual modalities. This enables a more seamless and intuitive user experience, as the companion can better understand the user’s needs and preferences.
- Autonomous Vehicles: Multi-modal AI systems play a crucial role in the development of autonomous vehicles, as they can process and analyze data from various sensors, such as cameras, LiDAR, and radar, to understand the vehicle’s surroundings and make informed decisions. This multi-modal approach is essential for ensuring the safety and reliability of autonomous vehicles.
- Healthcare: In the healthcare industry, multi-modal AI systems can analyze data from various sources, such as medical images, electronic health records, and patient-reported outcomes, to provide more accurate diagnoses and personalized treatment plans. This holistic approach to data analysis has the potential to revolutionize patient care and improve health outcomes.
By embracing the potential of multi-modal AI systems, we can revolutionize the way users interact with technology, creating experiences that are not only more efficient but also more enjoyable.
The future of AI lies in multi-modal systems that can perceive, understand, and reason in multiple modalities, providing users with the intelligent and adaptable tools they deserve.
With the advantages of multi-modal AI in mind, let’s introduce Kosmos — an innovative model that leverages this technology to deliver an intuitive and versatile user experience.
Democratizing Super-Intelligence with Kosmos-1
Agora, an organization dedicated to advancing humanity through open-source multi-modal AI research, is at the frontier of the Multi-Modal AI revolution.
We’re are actively working on the democratization of Kosmos-1, a super-intelligent AI model that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot) from Microsoft.
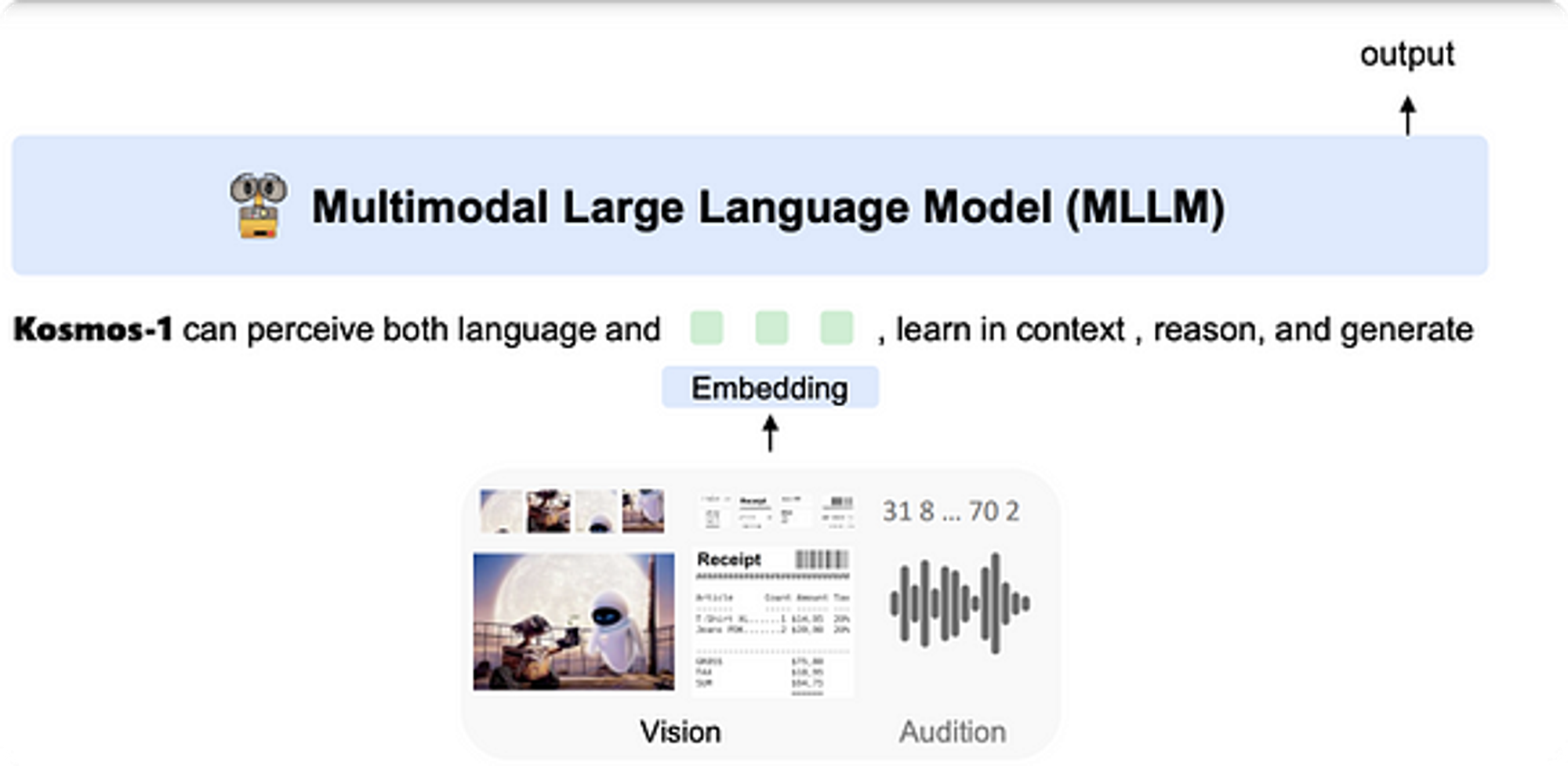
Kosmos-1 is a groundbreaking AI model that intuitively understands multiple modalities, such as text, vision, and audio, by embedding them into multi-modal sentences.
This unified intelligence allows users to ask questions about images or audio, providing a seamless and intuitive experience.
Here are some demonstrations from the paper!



The detailed descriptions of different categories for in-context image classification.

In-context verbal descriptions can help KOSMOS-1 recognize visual categories better.

MultiModal Chain of thought allows for models to deduct knowledge in multiple forms of data. This allows an entity to separate noise from signal in an embodied environment.

Top: An example of Raven IQ test. Bottom: Evaluate KOSMOS-1 on Raven IQ test.
The input prompt consists of the flattened image matrix and verbal instruction. We append each candidate image to the prompt separately and query the model if it is correct. The final prediction is the candidate that motivates the model to yield the highest probability of “Yes”. With some more training and chain of thought like datasets, this model will be able to achieve post Human iq scores.

Selected examples generated from KOSMOS-1. Blue boxes are input prompt and pink
boxes are KOSMOS-1 output. The examples include (1)-(2) image captioning, (3)-(6) visual question answering, (7)-(8) OCR, and (9)-(11) visual dialogue.

Here we can see a single model displaying general intelligence in a dialogue conversational form. This is the sprouting of a super intelligent embodied agent.
Learn more about Kosmos-1 here:
Papers with Code - Language Is Not All You Need: Aligning Perception with Language Models27 Feb 2023 · Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais…paperswithcode.com
Post Human Reasoning In Multiple Modalities:
Imagine a world where AI can not only understand language but also perceive and reason about everyday objects like never before. That's the world that KOSMOS-1 is ushering us into.
Now, let me tell you about the fascinating experiments Microsoft conducted to demonstrate the unparalleled capabilities of KOSMOS-1.
Microsoft took on the challenge of visual commonsense reasoning tasks – you know, the kind that require an understanding of everyday objects like color, size, and shape.
Microsoft compared KOSMOS-1's performance with that of a traditional language model, LLM, on three object commonsense reasoning datasets: RELATIVESIZE, MEMORYCOLOR, and COLORTERMS. In these tests, KOSMOS-1 emerged as the clear winner, showing that it can transfer its visual knowledge to language tasks with incredible ease.
Just look at these results! KOSMOS-1 outperformed LLM by 1.5% on RELATIVESIZE, 14.7% on MEMORYCOLOR, and a staggering 9.7% on COLORTERMS. This is a revolutionary development, my friends, proving that KOSMOS-1 can tap into its visual knowledge to excel in visual commonsense reasoning.
So, what does this mean for you?
It means that we're democratizing an AI that can understand the world in a way that was previously unimaginable.
KOSMOS-1 will not only change the way we interact with technology, but it'll also open up new horizons in fields like education, healthcare, and entertainment.
With KOSMOS-1, we're one step closer to building a future where AI can truly understand and reason about the world around us.
And, here are some potential broader implications of Kosmos-1 and Multi-Modal AI Models!
10 Use Cases for Kosmos-1
- Customer Support: Kosmos-1 could revolutionize customer support by understanding and resolving customer issues across multiple channels, potentially reducing response times by 50% and increasing customer satisfaction.
- Healthcare: Kosmos-1 could assist medical professionals in diagnosing diseases by analyzing medical images, patient records, and lab results, potentially reducing diagnostic errors by 30% and improving patient outcomes.
- Marketing: By analyzing consumer behavior across text, images, and audio, Kosmos-1 could help businesses create more targeted and effective marketing campaigns, potentially increasing conversion rates by 25%.
- Education: Kosmos-1 could provide personalized learning experiences by understanding students’ learning styles and preferences across various modalities, potentially improving learning outcomes by 20%.
- Recruitment: By analyzing job applicants’ resumes, portfolios, and video interviews, Kosmos-1 could help companies identify the best candidates, potentially reducing hiring costs by 15% and improving employee retention.
- Product Development: Kosmos-1 could analyze customer feedback, market trends, and competitor products across multiple modalities, helping businesses develop innovative products that meet customer needs, potentially increasing market share by 10%.
- Supply Chain Management: By analyzing data from various sources, such as text documents, images, and sensor data, Kosmos-1 could optimize supply chain operations, potentially reducing logistics costs by 20% and improving efficiency.
- Financial Analysis: Kosmos-1 could analyze financial data, news articles, and market trends to provide more accurate investment recommendations, potentially increasing portfolio returns by 15%.
- Smart Cities: By processing data from various sources, such as traffic cameras, social media, and sensor data, Kosmos-1 could help city planners make data-driven decisions, potentially reducing traffic congestion by 25% and improving overall quality of life.
- Entertainment: Kosmos-1 could analyze user preferences across text, images, and audio to provide personalized content recommendations, potentially increasing user engagement by 20% and boosting subscription revenue.
By harnessing the power of Kosmos-1, businesses and individuals can unlock endless new possibilities, save 1000s of hours, and improve efficiency by an immeasurable amount across various aspects of work and life.
And to achieve this ambitious goal, Agora needs help in training Kosmos-1.
We’re are currently configuring a training strategy for the model, optimizing it with state-of-the-art (SOTA) methods, and seeking a cloud provider or partner willing to provide the GPUs needed to train Kosmos-1.
And, we need help with optimizing the training strategy!
The open source code repositories will be linked below
Repository:
Main repo:
EXA/exa/models/KOSMOS_reimplementation-main at master · kyegomez/EXAThis repository is a rudimentary reimplementation of the KOSMOS-1 model described in Microsofts recent paper Language…github.com
Model code:
EXA/kosmos.py at master · kyegomez/EXAAn EXA-Scale repository of Multi-Modality AI resources from papers and models, to foundational libraries! …github.com
Training Strategies:
Vision
EXA/train_kosmos_original.py at master · kyegomez/EXAYou can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…github.com
Roadmap for Kosmos-1
- Configure dataset, training strategy, and optimize everything ready for training using SOTA methods: The first step in the development of Kosmos-1 is to configure the dataset and training strategy. This involves selecting the appropriate data sources, designing the training process, and optimizing the model for SOTA methods. For any questions or anything email me at [email protected]
- Find Cloud Provider willing to partner on training Kosmos: To train Kosmos-1 effectively, Agora needs a cloud provider that can support the computational requirements of the model. This partnership will be crucial in ensuring the successful development and deployment of Kosmos-1 and For any questions or anything email me at [email protected]
- Train
- Release everything for free
By democratizing Kosmos-1, Agora aims to make multi-modal AI accessible to everyone, empowering individuals and organizations to harness the power of superintelligent AI systems that can perceive, understand, and reason in multiple modalities.
Join us and advance Humanity!
Join Agora 💜

Agora is battling problems that left unattended would mean the end of our species and everything as we know it.
Multi-Modality AI has the power to help us overcome these problems and prosper for Eternity.
And, we’re devoted on bringing this long-awaited technology to everyday Human beings.
Join us now and write your mark on history for eternity!
In Conclusion,
In conclusion, the world of AI is evolving from the bumbling, one-trick pony uni-modal systems that left our dear Angus and Morag pulling their hair out, to the brave new frontier of multi-modal AI.
Kosmos-1 will revolutionize how we interact with technology, perceiving and understanding multiple modalities like a true technological superhero.
So, let’s bid farewell to the days of soggy haggis-like AI systems and say hello to the future, where our digital companions are as clever and adaptable as a Scottish chameleon.
Imagine a world where our AI-powered devices make life easier, not more frustrating.
Where voice assistants understand context and provide relevant answers, image recognition is accurate and reliable, and our digital world becomes a seamless, personalized experience.
That’s the future Agora envisions with the democratization of Kosmos-1.
So, raise your glasses and toast to the future of multi-modal AI.
As we leave behind the days of digital dunce caps, let’s welcome the era of superintelligent systems that bring the best of technology to every person on Earth!
Slàinte mhath!